




 Current Views: 349655
Current Views: 349655
 Current Downloads: 210828
Current Downloads: 210828
Advances in Linguistics Research
ISSN Print:2707-2622
ISSN Online:2707-2630
Contact Editorial Office



Subscribe to the latest published information from SCISCAN
Research on Quality Assessment of English Translation of Chinese Classics from the Perspective of Large Language Models—A Case Study of The Library of Chinese Classics


-
Information:
School of Foreign Languages, Xinjiang University, Urumqi, China
-
Keywords:
Large Language Models; English Translation of Chinese Classics; Text Type Theory; Translation Quality Assessment; The Library of Chinese Classics
- Abstract: This study takes nine works from The Library of Chinese Classics as its corpus, categorizes them into informative, expressive, and operative types based on Reiss’ Text Type Theory, with a total corpus of around 1,800 Chinese characters. With ChatGPT-5.4 and DeepSeek-V3.2 as test models, translation quality is assessed across accuracy, literary quality, and persuasiveness by employing the MQM error hierarchy scale, BLEU score, and BERT-based sentiment similarity analysis. The results show that for informative texts, DeepSeek-V3.2 registers a lower total error count (38.33) than ChatGPT-5.4 (57.67), and it outperforms the latter in minimizing undertranslation; for expressive texts, DeepSeek-V3.2 achieves a higher average BLEU score (18.89) than ChatGPT-5.4 (15.03), demonstrating better reproduction of poetic prosody; for operative texts, both models yield a cosine similarity score above 0.98, demonstrating comparable ability to deliver emotional nuances. Through comparative analysis, this paper aims to provide empirical evidence for the selection of intelligent translation models for classics of different text types, and to offer a reference for the quality improvement of Chinese culture outbound translation and the construction of a multi-dimensional assessment system.
- DOI: 10.35534/lin.0802014
- Cite: Wei, Z., & Bai, L. (2026). Research on Quality Assessment of English Translation of Chinese Classics from the Perspective of Large Language Models—A Case Study of The Library of Chinese Classics. Advances in Linguistics Research, 8 (2), 171-182.
1 Introduction
Chinese classics crystallize the intellectual essence of Chinese culture, embodying profound historical depth and philosophical wisdom. In the course of Chinese culture “going global”, the translation of these classics carries far-reaching significance. The rise of large language models (LLMs) has steered research on the English translation of Chinese classics into a new era of intelligence.
Existing studies generally proceed along two lines. The first is the assessment of domain-specific texts. For example, Liu Qiushi et al. (2026) combined Bilingual Evaluation Understudy (BLEU) with manual assessment to examine the terminological precision and complex sentence processing capacity of DeepSeek-V3 and Spark Desk in military text translation, concluding that both LLMs can produce high-quality specialized translations. Ren Yuxin et al. (2025), using BLEU, TER, METEOR, and expert scoring, demonstrated that ChatGPT-4 outperformed traditional neural machine translation in preserving the cultural connotations of traditional Chinese medicine terminology and in contextual appropriateness. The second line involves cross-model comparisons. Huang Xie’an and Zhao Shanjiang (2026) employed Coh-Metrix and Python to conduct a quality analysis of Chinese-to-English translation by eight mainstream domestic and international models, finding that domestic LLMs have begun to rival their overseas counterparts in translating classical Chinese into English. Yu Qiangfu and Wan Qizheng (2025) took Mencius as a case study, applying House’s model and the Multidimensional Quality Metrics (MQM) error hierarchy scale, and found that domestic models overall display superior cultural adaptability in translating core Confucian concepts.
Although these studies have yielded fruitful results, notable gaps remain. First, LLM-based research on the English translation of Chinese classics has largely focused on a single text type, without exploring performance differences across text types. Second, existing assessment dimensions concentrate predominantly on accuracy and literary quality, while the persuasiveness of texts is rarely addressed. In light of this, the present study draws on nine classic works from The Library of Chinese Classics (the Library) as its corpus, systematically covering three text types (informative, expressive and operative). It also adopts three assessment tools for comprehensive evaluation—MQM, BLEU, and Bidirectional Encoder Representations from Transformers (BERT)-based emotional similarity.
In the 1970s, Katharina Reiss put forward Text Type Theory, which divides texts into three categories: informative, expressive and operative (Munday et al., 2022). Informative texts—such as those on medicine, military affairs, and technological encyclopedias—primarily convey facts. Expressive texts, like poetry, emphasize emotional expression. Operative texts, such as simulated Hua-pen stories designed to exhort virtue and condemn vice, focus on admonition and appeal. These three text types frequently intertwine in Chinese classics. Sunzi: The Art of War, for example, contains passages that use rhetorical devices such as parallelism and antithesis to enhance persuasive effect, exhibiting operative features; however, the overarching purpose of the work is to impart military principles and tactical doctrines. Though it employs persuasive rhetoric, its core purpose is to convey military knowledge, so it is categorized as an informative text in this study. The texts selected below follow the same principle of classification.
The Library is a major national publishing project of considerable scale and influence, and it has become a model in the history of translation and cultural dissemination in China. The classics included in the Library span fields such as science and technology, literature, and history, and the breadth of their content gives rise to text diversity, making them an ideal object of study through the lens of Reiss’ Text Type Theory. Moreover, the poetic works collected in the Library were largely translated into English by master translators such as Xu Yuanchong, and their translations are noted for poetic expressiveness and metrical rigor, thus providing authoritative reference standards for the subsequent BLEU-based literary quality assessment. For these reasons, this study selects nine classics from the Library and classifies them according to their primary text type, as shown in Table 1.
In line with the three text types, targeted assessment frameworks are established. For informative texts, where the core function is factual transmission, the study employs the MQM error hierarchy scale, focusing on addition, mistranslation, and undertranslation to gauge translation accuracy. For expressive texts that foreground aesthetic and formal qualities, the study introduces BLEU score measurement and, through specific case analyses, examines the degree of literary representation in terms of word choice, blankness, and rhyme. For operative texts that aim to appeal to the reader, the study draws on the BERT model to measure emotional intensity and conduct cosine similarity analysis, so as to assess how effectively the translation conveys the emotional tenor.
Table 1 Text Types of the Classics in the Library
|
Text Type |
Classics in the Library |
|
Informative |
Yellow Emperor’s Canon of Medicine: Plain Conversation |
|
Sunzi: The Art of War |
|
|
Tian Gong Kai Wu |
|
|
Expressive |
Selected Poems of Li Bai |
|
Selected Poems of Su Shi |
|
|
The Complete Works of Tao Yuanming |
|
|
Operative |
Stories Old and New |
|
Stories to Caution the World |
|
|
Stories to Awaken the World |
Given the inherent instability of LLMs—role-based prompts can activate domain-specific knowledge or stylistic features, so different instructions can yield different outputs (Zhao et al., 2024)—the authors conducted three translation tests for each of the two LLMs using different prompts. The first test used the instruction “Please translate the following text into English”; these translations are referred to below as GPT 1 and DS 1. The second test used “Suppose you are an experienced translator, please translate the following text into English”; these translations are abbreviated as GPT 2 and DS 2. The third test used “Suppose you are a senior expert in Chinese classics, please translate the following text into English”; these are designated GPT 3 and DS 3. For ease of reference, the elements analyzed in the examples that follow are underlined.
2 Informative Texts: Accuracy
The assessment criteria are based on the MQM framework. Major accuracy-related errors include mistranslation, overtranslation, undertranslation, addition, omission, violation of the “do not translate” principle, and untranslated source text (Jia, 2024). This chapter focuses on three dimensions—addition, mistranslation, and undertranslation—to assess the accuracy performance of LLMs’ translations.
Table 2 Total Number of MQM Errors in LLM Translations
|
Error Type |
GPT 1 |
GPT 2 |
GPT 3 |
DS 1 |
DS 2 |
DS 3 |
|
Addition |
17 |
17 |
18 |
8 |
17 |
18 |
|
Mistranslation |
13 |
10 |
11 |
16 |
12 |
13 |
|
Undertranslation |
28 |
30 |
29 |
7 |
10 |
14 |
|
Average Total Errors Per Model |
57.67 |
38.33 |
||||
Note: “Average total errors per model” refers to the sum of the three error types for each model divided by 3.
The source text for Case 1 is excerpted from Shanggu Tianzhen Lunpian of Yellow Emperor’s Canon of Medicine: Plain Conversation (263 Chinese characters). Case 2 is selected from the “Making Assessments” chapter of Sunzi: The Art of War (242 characters), and Case 3 comes from the first chapter of Tian Gong Kai Wu (213 characters). The experimental results are shown in Table 2.
As can be seen from the table, among the two LLMs, DS translations exhibit a lower average total number of errors, and the occurrence of undertranslation is markedly lower than in GPT translations. The following sections select typical cases and further examine the translations of the two models from the three dimensions through illustrative examples.
2.1 Addition: Explicitation
Addition is one common form of explicitation in translation, whereby the translator supplements implicit information in the source text according to differences in language usage or contextual information (Li & Zhang, 2020). As shown in the table, with the exception of DS 1, all other translations show similar frequencies of explicit additions. This phenomenon commonly appears in the phrase “生谷数粒” in Case 3.
The original text: 秧过期老而长节,即栽于亩中,生谷数粒,结果而已。 (Song, 2011)
GPT 1-3: “...each stalk/each plant will produce only a few grains...”
DS 2: “...they will yield only a few scattered grains per stalk...”
DS 3: “...each plant will yield but a few grains...”
The corresponding modern Chinese version is “育秧期已过而仍不插秧, 秧就要老而长节, 即使栽到田里也不过长几粒谷, 不会再结更多谷实了” (If the nursery period has passed and the seedlings have not yet been transplanted, they will become overgrown and develop nodes; even if planted in the field, they will yield only a few grains and nothing more). The intended meaning is thus that the seedlings themselves will produce only a few grains, as DS 1 renders it “If the seedlings become overgrown and develop nodes... they will only produce a few grains.” The other five translations, however, all explicitly add “each stalk” or “each plant”. The reason may be that LLMs, following English idiomatic conventions, tend to insert what they consider reasonable, such as a quantifying unit for a countable plural noun, making the translation appear smoother or more logical on the surface, while in fact adding extra information not present in the original.
2.2 Mistranslation: Negentropy
The negentropy of information in translation arises largely from translators’ insufficient command of the source text’s cultural context, which makes it impossible for translations to fully deliver the original meaning (Jiang & Lin, 2020). According to the statistical results of this section, all model translations show roughly the same frequency of semantic distortion. The most prominent divergence occurs in the interpretation of “卑而骄之” in Case 2.
The original text: 故能而示之不能……卑而骄之,佚而劳之…… (Sun, 1999)
GPT 1: “...encourage his arrogance by humility...”
GPT 2: “...appear humble to make him arrogant...”
GPT 3: “...humble yourself so as to make him arrogant...”
DS 1: “...discourage them when they are arrogant...”
DS 2-3: “...make him arrogant when he is humble...”
Multiple interpretations of “卑而骄之” exist in the scholarly community. The corresponding modern Chinese version
in the Library is “敌人辞卑慎行, 就要骄纵他” (When the enemy speaks humbly and acts cautiously, you should
make him arrogant). Xia Mingxing (2020) points out that the “卑” in “卑而骄之” refers to a characteristic of the enemy
at hand, as it is parallel to the preceding “怒而挠之 (if the enemy is irascible, irritate him)”. Feng Kaibao (2021) also
holds that “怒而挠之, 卑而骄之” means deceiving the enemy. This paper adopts this interpretation. Within the interpretive
framework adopted here, the DS translations are closer to this understanding, as DS 2-3 reproduce the original meaning. The other translations, by adopting different strategies and rendering the phrase as “encourage the enemy’s arrogance by humility” or “make oneself humble to make the enemy arrogant”, diverge from the interpretation adopted in this
paper.
2.3 Undertranslation: Foreignization
Previous research has defined undertranslation as a type of pragmatic failure (Sun & Hou, 2025), and some scholars regard the loss of cultural elements as a key feature of undertranslation (Zhang & Chen, 2023). So this paper examines the phenomenon of undertranslation along two dimensions: pragmatic undertranslation, which refers to the translation’s failure to explicitate the specific information carried by the source text, such as the precise conveyance of age; and cultural undertranslation, which refers to the loss of the source text’s cultural connotations, such as the conceptual explicitation of traditional Chinese medicine terms. As Table 2 shows, undertranslation occurs far more frequently in GPT outputs than in DS outputs, mainly because GPT relies heavily on rigid literal translation, preserving the original form of classical Chinese but causing semantic vagueness and cultural default. This is most evident in the pragmatic undertranslation of age expressions and the cultural undertranslation of terms such as “天癸” and “地道” in Case 1.
The original text: 女子七岁……二七……七七
丈夫八岁……二八……八八 (Liu & Li, 2008)
GPT 1-3: “At twice seven” / “At two times seven” / “At two sevens” ... “At seven times seven” / “At seven sevens” ...
“At twice eight” / “At two times eight” / “At two eights” ... “At eight times eight” / “At eight eights.”
DS 1-3: “At fourteen,” “At forty-nine,” “At sixteen,” and “At sixty-four.”
The original “二七” “七七” “二八” and “八八” are specific age designations in traditional Chinese medicine for life cycles, carrying precise numerical information. GPT 1-3 all adopt a foreignization strategy: their literal renderings formally preserve the multiplicative structure of classical Chinese, but fail to convey the specific ages clearly to the target reader. In contrast, DS 1–3 all adopt a domestication strategy, directly translating the specific ages and making the information immediately clear, while GPT retains the traditional Chinese numerical structure through foreignization.
Moreover, GPT mostly translates “天癸” as “the heavenly gui” and “地道” as “the Earthly Passage”, whereas DS translates them as “Tiangui” and “the reproductive passage”, which are closer to the reference translations (by Li Zhaoguo): “Tiangui” and “menstruation.” Thus, in the transmission of cultural information in informative texts, DS overall outperforms GPT in factual accuracy and clarity.
This chapter has assessed the translation accuracy of informative texts based on the MQM scale. The results show that DS exhibits a lower overall error rate, with a significant advantage particularly in the domestication treatment of numerical expressions and TCM terminology. The two models demonstrate similar frequencies of mistranslation, while GPT is more prone to redundant addition. Overall, DS surpasses GPT in the accuracy of transmitting information in Chinese classics.
3 Expressive Texts: Literary Quality
BLEU evaluates the similarity between machine translations and reference translations by calculating n-gram overlap (Wang & Wen, 2010). This chapter adopts the translations of Xu Yuanchong and Wang Rongpei as reference standards, since the literary merit of their versions is widely acknowledged in the scholarly community. BLEU scores are therefore used to measure the degree of similarity between the model translations and these reference translations: the higher the similarity, the closer the literary quality. On this basis, the chapter employs manual assessment as its primary method, so as to assess translation performance more comprehensively.
Case 1 consists of three poems from Selected Poems of Li Bai, with a total of 137 Chinese characters. Case 2 is taken from Selected Poems of Su Shi, consisting of “It Snowed on the Night of the 14th Day of the 12th Lunar Month. I went to the Southern Valley on the Next Morning and Drank There Till Dusk, “Spring Night” and “Lady Yu’s Tomb” totaling 136 characters. Case 3 is drawn from The Complete Works of Tao Yuanming, comprising “Naming My Son” with a total of 130 characters. The results are shown in Table 3.
Table 3 BLEU Scores (%) of LLM Translations
|
Case |
GPT 1 |
GPT 2 |
GPT 3 |
DS 1 |
DS 2 |
DS 3 |
|
Case 1 |
6.88 |
2.14 |
4.53 |
11.69 |
2.78 |
7.44 |
|
Case 2 |
9.18 |
10.52 |
7.37 |
12.64 |
8.23 |
10.21 |
|
Case 3 |
1.33 |
1.48 |
1.66 |
1.17 |
1.35 |
1.15 |
|
Average Total Score Per Model |
15.03 |
18.89 |
||||
Note: “Average total score per model” refers to the sum of the BLEU scores across the three cases for each model divided by 3
As can be seen, DS translations achieve higher similarity with reference translations than GPT translations do, with DS 1, in particular, achieving a markedly higher BLEU score than the other versions. The following analysis, therefore, focuses on the DS translations. In assessing the literary quality of the translations, this chapter draws on the functional-pragmatic principles proposed by Juliane House, assessing the LLM translations at the pragmatic, semantic, and textual levels (House, 2015).
3.1 Semantics: Word Choice
A single well-chosen word can fully embody the artistic conception of a poem. Traditional Chinese literary culture places great emphasis on word choice, or the refining of words, in order to condense as much feeling as possible into a mere few dozen characters. Poets pay particular attention to the art of diction (Wang, 2008). Hence, in the English translation of classical Chinese poetry, the ability to accurately reproduce such special lexical features as reduplicative words is an important yardstick for measuring translation quality. The three reduplicative phrases in Case 3, “纷纷战国” “浑浑长源” and “蔚蔚洪柯” serve as examples.
The reference translation: “When the Warring States disturbed the mind.
The river surged to the sea.
Profuse and lavish grew the tree.” (Tao, 2003)
DS 1: “In chaotic Warring States,
A deep and long source,
Lush and mighty branches.”
DS 2: “When Warring States ran wild,
A deep, long source, a mighty tree—
Its streams, its boughs extend.”
DS 3: “When the Warring States in wild disorder swirled,
A deep and endless source, a mighty bole—
Its streams diverge, its myriad branches spread.”
GPT translations predominantly render these reduplicatives as adjectives or nouns, e.g., “Tumultuous” / “In the tumult of,” “Vast,” “luxuriant.”
The reference translation (by Wang Rongpei) translates “纷纷” “浑浑” and “蔚蔚” all as verb phrases. Among all the versions, DS 2-3 are closest in terms of part of speech, also using verb phrases to convey the states of “wars being frequent and chaotic,” “great waters surging,” and “plants growing luxuriantly”. At the same time, a verbal mode of rendering effectively enhances the readability and acceptability of the translation, generating a dynamic, life-filled vigor that captures and sustains the reader’s attention. The other versions all resort to adjectives or noun phrases, tending towards a more static presentation and falling short in aesthetic tension.
3.2 Pragmatics: Blankness
Blankness is originally an artistic technique in Chinese painting, and the classical poetic principle of “words end but meaning lingers” resonates closely with the painting technique of blankness (Cai, 2009). From the perspective of reception aesthetics, a literary work is itself a schematic structure filled with “spots of indeterminacy” and “blanks”, which the reader must fill in with their own experience and imagination (Ren, 2022). Thus, the more indeterminacies a text has, the more it encourages readers to engage actively with the work, enlivening the reading process through the reader’s active involvement. The following discussion takes the line “思君不见下渝州” from “The Moon over the Eyebrow Mountains” as an example.
The reference translation: “O Moon, how I miss you when you are out of view!” (Li, 2007)
GPT 1-3: “Thinking of you, yet not seeing you, I drift down to/toward Yuzhou.”
DS 1: “O Moon, you’re missed, but unseen, to Yuzhou I go.”
DS 2-3: “Thinking of you, my friend unseen, / my unseen friend down to Yuzhou I’m going.”
The reference translation (by Xu Yuanchong) renders “君” as the ambiguous “O Moon”, avoiding a direct indication of the object of longing, and the exclamatory “how I miss you” is emotionally restrained. Different models handle this in different ways. DS 1 is closest in style to Xu’s version; although “but unseen” is slightly awkward logically, it similarly uses “O Moon” to convey a veiled emotion. In contrast, DS 2-3 adds “my friend”, destroying the blankness and pinning the sentiment down to a specific addressee. All three GPT versions render the line as “Thinking of you”, but without a clear antecedent in the context, “you” tends to confuse the reader into identifying a specific person, closing off the polysemy of the original poem.
3.3 Textuality: Rhyme
Sound is the fundamental vehicle of aesthetic expression and the most immediate manifestation of “each form bearing its own beauty”. Poetry is a luminous gem in the history of Chinese literature, containing richly beautiful rhyme and rhythm (Li & Kuang, 2026). Preserving the original rhythmic qualities in translation is crucial. This section takes the poem “It Snowed on the Night of the 14th Day of the 12th Lunar Month” from Case 2 as an example.
The original text: 南溪得雪真无价,
走马来看及未消。
独自披榛寻履迹,
最先犯晓过朱桥。 (Su, 2007)
The reference translation: ending with “indeed,” “away,” “reed,” “day”.
GPT 1-3: ending with “price,” “disappeared” / “away,” “footprints” / “footsteps,” “bridge”.
DS 1: ending with “priceless” “away” “footprints” “day”.
DS 2-3: ending with “untold” “old” / “cold” “deep” “peep”.
The original poem uses an alternating “ao” rhyme on the even lines: the level-tone rhyme character “消” stretches out long and smooth, accentuating the leisurely mood of the poet riding in search of snow; the rising-tone rhyme character “桥” falls with a modulated turn, and the rhythmic interplay of level and deflected tones heightens the sense of a sudden open clarity when crossing the bridge at dawn. Xu’s translation closes the first line with /ˈdiːd/, where the long vowel /iː/ followed by the voiced stop /d/ creates a lingering yet solid syllable. The second line ends with the diphthong /eɪ/, the mouth gliding from mid to high, mimicking the motion of horse hooves treading on snow and gradually receding. The third line repeats the /iːd/ sound group, echoing the end rhyme of the first line from a distance; the fourth line again ends with /eɪ/, alternating with the second line. Thus, the four lines of the whole poem form an ABAB rhyme cycle of /iːd/→ /eɪ/→ /iːd/→ /eɪ/, endowing the translation with a harmonious sonic beauty.
GPT 1-3 have no fixed end rhymes or consistent rhyming pattern; their line endings are irregular and lack the rhythmic beauty typical of poetry. DS 1 similarly uses an ABAB rhyme: “priceless” and “footprints” produce a near rhyme with /əs/ and /ts/ echoing each other, while “away” and “day” form a strict /eɪ/ rhyme; the end rhymes of the four lines interlace, and the light /ts/ ending of the third line builds momentum for the rising diphthong /eɪ/ of the fourth line, with prominent phonetic symbolism. DS 2-3 adopt a different AABB rhyme pattern: the first two lines share the /oʊld/ rhyme, where the liquid /l/ and voiced stop /d/ make the end rhyme steady and weighty, matching the heavy stillness of snow covering a cold creek; the long vowel /iː/ in the final two lines is crisp and bright, sketching the faint gleam of dawn light when crossing the bridge at daybreak.
This chapter has assessed the reproduction of literary quality in expressive texts by combining BLEU scores with functional-pragmatic principles. The cases show that DS exhibits a higher overall similarity to the authoritative translations. Across the three dimensions of word choice, blankness, and rhyme, DS is more adept at conveying spirit through verbs, preserving poeticness through implicitness, and structuring rhythm through rhyme schemes, outperforming GPT in expressiveness.
4 Operative Texts: Persuasiveness
BERT model can vectorize texts and perform sentiment analysis to obtain sentiment values (Wang & Tao, 2025). This chapter uses Python and the BERT library to compute sentiment scores for seven translated texts and adopts cosine similarity to examine how closely LLM translations match reference versions in emotional expression. The closer the score is to 1, the more consistent the emotional expression of the translation is with the reference version.
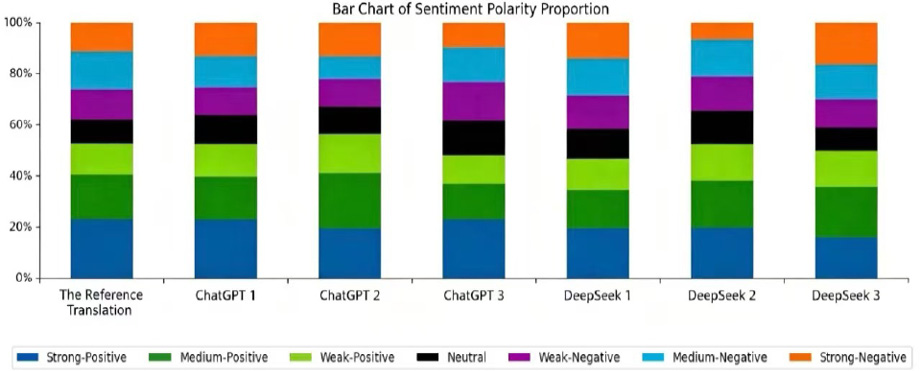
Figure 1 Distribution of Seven Sentiment Intensities Across Seven Translations
The cases in this chapter are drawn from Volume 32, “Humu Di Intones Poems and Visits the Netherworld” of Stories Old and New; Volume 1, “Yu Boya Smashes His Zither in Gratitude to an Appreciative Friend” of Stories to Caution the World; and Volume 1, “Two High-minded County Magistrates Vie to Take On an Orphan Girl as Daughter-in-Law” of Stories to Awaken the World, totaling 656 Chinese characters. The reference translations are all by Yang Shuhui, Professor of Chinese Literature at Bates College in the United States, and Yang Yunqin, a simultaneous interpretation expert at the United Nations. The sentiment percentages for each translation are detailed in Figure 1.
Cheng Wei et al. (2017) found that common similarity calculation methods include cosine similarity, Dice coefficient, and Jaccard coefficient, with the latter two being algorithmically similar in nature. This paper, therefore, adopts cosine similarity as the calculation method and obtains the average emotional cosine similarity between the translations of the two types of LLMs and the reference translations, as shown in Table 4.
Table 4 Average Cosine Similarity of LLM Translations
|
Model |
Average Cosine Similarity |
|
GPT 1-3 |
0.9852 |
|
DS 1-3 |
0.9821 |
As can be seen, the two models perform equally well in capturing and reproducing emotional tones, both achieving a high degree of agreement with the reference translations. In text sentiment analysis, a sentence can be treated as a short text and used as the basic unit of discourse analysis (Wu & Yao, 2024). To examine the actual performance of the above similarity at the sentence level, the following takes syntactic translation as an example, with a case drawn from the classic episode of Yue Fei’s wrongful conviction, which epitomizes the core theme of Hua-pen stories—praising loyalty and condemning treachery.
The original text: 大理寺卿薛仁辅等讼飞之冤;判宗正寺士㒟,请以家属百口,保飞不反;枢密使韩世忠愤愤不平,亲诣桧府争论,俱各罢斥。 (Feng, 2006)
All LLM translations render this passage into three parallel structures, e.g., “Xue Renfu… pleaded/petitioned...Zhao Shiniao…offered...Han Shizhong… argued...”, arranging the protest actions of the three officials in parallel through complete subject-predicate-object constructions separated by semicolons or periods. Although there are slight differences in the translation of individual verbs, the syntactic structure is completely consistent with the reference translation. This paratactic relationship forges a semantic synergy without the need for conjunctions; each independent clause describes an act of loyalty and integrity, and these descriptions together create a strong sense of collective protest akin to “the entire court seething with indignation”. The first clause describes a court official petitioning for the injustice, setting a tone of righteousness; the second clause strengthens the credibility of the loyal official with a member of the imperial clan staking a hundred lives on his guarantee; the final clause depicts the Commissioner of Military Affairs personally going to the chancellor’s residence to argue, bringing the indignation to a climax. Moving from civil official, to imperial clan, to military commander, and from written memorial, to personal guarantee, to direct confrontation, the three clauses escalate step by step in rank and intensify layer by layer in emotion, allowing the reader to perceive the weight of emotion through the very density of the syntactic arrangement.
Based on the sentiment intensity similarity data, it is evident that LLMs can accurately capture and reproduce the core emotional orientation of the original text when processing literary texts with strong emotional coloring. The two models are evenly matched, both capable of faithfully replicating the emotional tone of the reference translations.
5 Conclusion
In summary, DeepSeek-V3.2 outperforms ChatGPT-5.4 in translating informative and expressive texts, whereas the two models show equivalent performance in conveying emotions in operative texts. It should be noted, however, that the experimental corpus is relatively small, so the findings are still preliminary. Future studies shall expand the corpus and introduce manual evaluation to improve the reliability of research results. The above differences may be attributable to the limited breadth and depth of training data on the Chinese classics in models developed outside of China, whereas the convergence observed in the emotional dimension suggests that mainstream LLMs have already acquired a certain general capability in cross-lingual emotion capture. This study verifies the feasibility of applying Text Type Theory to the assessment of LLM translation quality: different text types impose distinct requirements on translation accuracy, literary quality, and persuasiveness, profoundly reflecting the intrinsic relationships among training data, model architecture, and textual function.
This study still has several limitations. In terms of the assessment method, no inter-annotator agreement test was conducted for MQM error annotation, and the lack of manual evaluation criteria weakens the validity of the results. BLEU scores are primarily based on surface-level n-gram matching and are, therefore, limited in their ability to capture the deep semantic and rhetorical features of expressive texts such as poetry. In terms of experimental design, variables such as model output length were not uniformly controlled, and translations were not produced through multiple runs with averaged results, which may affect output stability.
Future research can be deepened along the following lines. First, human expert assessment and post-editing efficiency should be incorporated into the assessment framework, establishing a three-dimensional quality evaluation model that integrates automatic assessment, human judgment, and editing cost. Meanwhile, metrics such as COMET and VADER should be introduced, and dedicated assessment metrics tailored for classical Chinese-to-English translation should be developed, incorporating dimensions such as rhythm, imagery, and culture-loaded terms. Second, reproducible comparative experiments across different models should be conducted under strictly controlled output conditions.
References
[1] Cai, H. (2009). Better blankness than diction—beyond poetic loss in translation. Foreign Languages in China, 6(3), 92–99.
[2] Cheng, W., Xian, Y. T., Zhou, L. J., Yu, Z. T., & Wang, H. B. (2017). A cross-lingual document similarity calculation method based on bilingual LDA. Computer Engineering & Science, 39(5), 978–983.
[3] Feng, K. B. (2021). From “knowledge victory” to “potential victory”: Sun Tzu’s orientation on the function of intelligence. Journal of Intelligence, 40(12), 8–13.
[4] Feng, M. L. (2006). Stories Old and New IV. (S. H. Yang & Y. Q. Yang, Trans., p. 1352). Changsha: Yuelu Publishing House.
[5] House, J. (2015). Translation Quality Assessment: Past and Present. London & New York: Routledge.
[6] Huang, X. A., & Zhao, S. J. (2026). An empirical comparative study on Chinese-English translation quality of large language models (LLMs). Language and Translation, (1), 50–59+66.
[7] Jia, Y. F. (2024). Integrating translation project management platforms with generative AI technologies: An investigation into the translation process through human-machine interaction. Foreign Language Teaching and Research, 56(6), 937–949+961.
[8] Jiang, J., & Lin, J. H. (2020). A case study of the realization of negentropy equivalence in translation—take the English version of the Analects of Confucius by Gu Hongming and James Legge as an example. Journal of Heilongjiang Institute of Teacher Development, 39(1), 137–141.
[9] Li, B. (2007). Selected Poems of Li Bai. (Y. C. Xu, Trans., p. 7). Changsha: Hunan People’s Publishing House.
[10] Li, X. Y., & Kuang, Y. W. (2026). Poetic reconstruction in the translation of rhymed classics: A study on the English translation of the Three-Character Classic from the perspective of cultural awareness. Foreign Language Research, (2), 16–22.
[11] Li, Y., & Zhang, H. (2020). Operational norms of additive explicitation of formulaic language in Chinese-English interpreting in the political field. Chinese Translators Journal, 41(4), 162–171.
[12] Liu, X., & Li, Z. (Trans.). (2008). Yellow Emperor’s Canon of Medicine: Plain Conversation (p. 4–6). Xi’an: World Publishing Corporation.
[13] Liu, Q. S., Ming, R. L., & Li, J. Y. (2026). A study on the translation quality assessment of generative AI in military intelligence. Defense Industry Conversion in China, (4), 35–37.
[14] Munday, J., Pinto, S. R., & Blakesley, J. (2022). Introducing Translation Studies: Theories and Applications. London & New York: Routledge.
[15] Ren, W. D. (2022). Reception aesthetics: A keyword in critical theory. Foreign Literature, (4), 108–118.
[16] Ren, Y. X., Chen, Z. J., Lin, Y. Z., & Liu, P. (2025). Research on machine translation quality evaluation of traditional Chinese medicine terminology in the artificial intelligence era: A case study of ChatGPT-4 and Google Translate. Guiding Journal of Traditional Chinese Medicine and Pharmacy, 31(12), 284–293.
[17] Song, Y. X. (2011). Tian Gong Kai Wu. (J. X. Pan, Modern Chinese Trans.; Y. J. Wang, H. Y. Wang, & Y. C. Liu, English Trans., p. 4–6). Guangzhou: Guangdong Education Publishing House.
[18] Su, S. (2007). Selected Poems of Su Shi. (Y. C. Xu, Trans., p. 14–15). Changsha: Hunan People’s Publishing House.
[19] Sun, H. T., & Hou, G. J. (2025). An eco-pragma-translatological critique of three English versions of the Tang poem Mosquito Troops Mustered Up. Journal of Liming Vocational University, (1), 43–51.
[20] Sun, W. (1999). Sunzi: The Art of War. (R. S. Wu, & X. L. Wu. Modern Chinese Trans.; W. S. Lin, English Trans.). Beijing: Foreign Languages Press, 6.
[21] Tao, Y. M. (2003). The Complete Works of Tao Yuanming. (Z. Q. Xiong, Modern Chinese Trans.; R. P. Wang, English Trans., p. 3, 5). Changsha: Hunan People’s Publishing House.
[22] Wang, F. (2008). An analysis of obstacles in the aesthetic transmission of classical Chinese poetry translation into English. Foreign Languages and Their Teaching, (2), 57–60.
[23] Wang, J. Q., & Wen, Q. F. (2010). A review of automated scoring systems at home and abroad: Implications for automated scoring of Chinese students’ translations. Foreign Language World, (1), 75–81+91.
[24] Wang, Z. X., & Tao, L. C. (2025). A study on the affective translation and dissemination of Li Sao: A human-machine comparative perspective. Foreign Languages Research, 42(4), 101–106.
[25] Wu, H., & Yao, X. D. (2024). A study on overseas reception of the English translation of Zhuangzi based on Python sentiment analysis. Foreign Studies, 12(4), 81–90+96+106–107.
[26] Xia, M. X. (2020). “Make him arrogant when he is humble” and famous generals and battles. Martial Historical Facts, (1), 53–56.
[27] Yu, Q. F., & Wan, Q. Z. (2025). Assessing the translation quality of classical Chinese texts by large language models: A case study of Mencius: Liang Hui Wang I. Chinese Science & Technology Translators Journal, 38(3), 50–53+57.
[28] Zhang, S. S., & Chen, Z. R. (2023). Explicitation in English translation of Chinese essays: A case study of Selected Modern Chinese Essays by Zhang Peiji. Journal of Jiangsu Ocean University (Humanities & Social Sciences Edition), 21(5), 91–100.
[29] Zhao, Y., Zhang, H., & Yang, Y. C. (2024). Comparative study on the translation quality of large language models—taking the translation of ‘Fan Hua’ as an example. Technology Enhanced Foreign Language Education, (4), 60–66+109.



