




 Current Views: 2402195
Current Views: 2402195
 Current Downloads: 1490384
Current Downloads: 1490384
Psychology of China
ISSN Print:2664-1798
ISSN Online:2664-1801
Contact Editorial Office



Subscribe to the latest published information from SCISCAN
基于小样本不均衡数据的汉语发展性阅读障碍预测模型
A Prediction Model for Developmental Dyslexia in Chinese Based on Small Sample and Imbalanced Data


-
Information:
新疆师范大学心理学院,乌鲁木齐
-
Keywords:
Developmental dyslexia in Chinese; SMOTEENN oversampling; Stacking ensemble; Small sample imbalanced data; Predictive model汉语发展性阅读障碍; SMOTEENN过采样; Stacking集成; 小样本不均衡数据; 预测模型
- Abstract: Early identification of developmental dyslexia (DD) is constrained by small samples and class-imbalanced data in real classrooms, and it remains unclear whether DD predictors vary across grade levels. Based on reading and cognitive ability assessments of 219 elementary school children in grades 1~5, this study constructs a predictive model by integrating SMOTEENN oversampling with stacking ensemble learning techniques, and employs SHAP analysis to identify key predictors and their grade-level differences. Results show: (1) phonological awareness and reading accuracy are core predictors of DD, maintaining significant contributions across all grades; (2) grade-specific modeling reveals that DD prediction in lower grades (1~3) primarily relies on “basic cognitive abilities” (e.g., fluent pinyin reading), whereas in higher grades (4~5) it shifts toward “reading efficiency indicators” (e.g., reading accuracy and fluency), highlighting the developmental changes in reading and cognitive measures associated with DD prediction. This study offers a feasible solution for DD prediction under conditions of small samples and imbalanced data, and provides psychological evidence for understanding the cognitive development trajectory of DD and enabling grade-specific, precise screening. 发展性阅读障碍(DD)的早期识别在真实教学场景中面临小样本与不均衡数据限制,且DD的预测因子是否随年级发展而变化尚不明确。基于对219名1~5年级小学儿童的阅读与认知能力的测评数据,融合SMOTEENN过采样与Stacking集成学习技术构建预测模型,并利用SHAP分析技术识别核心预测因子及其年级差异。结果发现:(1)语音意识与阅读准确性是DD的核心预测因子,二者在不同年级均保持重要贡献;(2)分年级建模显示,低年级(1~3年级)DD的预测主要依赖“基础认知能力”(如拼音朗读流畅性),而高年级(4~5年级)则转向“阅读效率指标”(如阅读准确性、阅读流畅性),揭示了预测DD的阅读和认知能力指标的发展性变化。本研究为小样本、不均衡数据条件下的DD预测提供了可行方案,也为理解DD的认知发展轨迹及分年级精准筛查提供了心理学依据。
- DOI: 10.35534/pc.0806146
- Cite: 杨智予, 姜小婷, 博思坦·马合木提江, 杨若涵. (2026). 基于小样本不均衡数据的汉语发展性阅读障碍预测模型. 中国心理学前沿, 8 (6), 988-998.
1 问题提出
发展性阅读障碍(Developmental Dyslexia,DD)是一种神经生物学的特殊学习障碍(Lyon et al.,2003),表现为智力正常但阅读、拼写存在显著困难(Kaisar,2020)。阅读能力低下不仅会严重影响儿童的学业成绩,还可能对其认知、情感、自我概念以及社会性发展产生重大影响(陈建军 等,2025)。据估算,全球约5%~17%的学龄儿童受DD影响(Gabrieli,2009),我国汉语发展性阅读障碍的发生率约为5%~10%(Yang et al.,2022)。据此估算有上千万儿童面临困境。因此,构建精准、高效的预测模型,实现对DD风险儿童的早期识别,具有重要的理论与实践意义。
传统研究方法(如相关分析或方差分析)难以充分捕捉这些预测因子与阅读障碍之间存在的复杂非线性关系及交互作用(Wang & Bi,2022)。近年来,机器学习技术因其在复杂数据模式识别、非线性关系建模和高维特征处理等方面表现出强大的性能,许多研究者尝试将其用于构建DD预测模型,进而提高筛查的精度与敏感性(卜晓鸥 等,2023)。研究整体趋势体现为:从使用传统机器学习算法走向深度学习算法,以获取最优参数(Shamir et al.,2019;Usman & Muniyandi,2020;Vajs et al.,2022;Man Kit Lee et al.,2023;王懋云 等,2025)。尽管现有研究取得了一定进展,但仍存在以下三个主要局限。
第一,数据条件与真实教育场景脱节。一方面,部分研究依靠眼动、脑电等精密仪器采集的高维神经生理数据,虽能以较小样本构建高性能模型,但其采集成本高昂、流程较为复杂,难以在实际的教学环境中大规模普及应用(Płoński et al.,2017;Vajs et al.,2022);另一方面,认知行为数据虽容易获取且更适用于大规模筛查,但通常依赖大样本且类别均衡的数据集才能构建出高性能的预测模型(Wang & Bi,2022;Man Kit Lee et al.,2023)。在真实小样本、不均衡数据条件下,认知行为数据能否通过适当的技术处理构建出高精度模型,尚缺乏系统探索。因此,探索适用于此类数据的建模方法成为迫切需要。
第二,汉语DD的核心认知预测因子尚存争议。已有研究从不同理论视角出发,识别出多种可能的认知缺陷。有研究者认为,正字法意识是汉语阅读障碍的核心认知缺陷(Perfetti et al.,2006;董琼 等,2012;Yeung et al.,2016)。还有研究者认为,语素意识对汉语阅读能力的发展更为重要(Shu et al.,2006;Tong et al.,2017)。除此之外,语音意识和快速命名也被大量研究证实其对于儿童汉语阅读发展的重要性,并表现出跨语言的一致性(徐世勇 等,2001;孟祥芝 等,2004;McBride-Chang et al.,2006;Chen et al.,2009;Liu & McBride-Chang,2010;任梦洁,申仁洪,2024)。然而,也有研究者认为,语音意识缺陷可能不是汉语发展性阅读障碍的主要缺陷,其不能准确预测儿童的阅读水平(Ho et al.,2002)。这种争议恰恰说明汉语阅读障碍成因的复杂性与多维性,也凸显了从数据驱动视角客观识别核心预测因子的必要性。
第三,核心预测因子的重要性是否随年级发展而变化,尚缺乏系统考察。阅读能力的发展具有阶段性(Goswami,2015),低年级儿童可能更多依赖基础认知技能(如拼音、语音意识),而高年级儿童则可能转向阅读效率指标(如阅读流畅性、准确性)。纵向研究也表明,快速命名和语音意识对阅读能力的预测作用在不同年级呈现动态变化(Blockmans et al.,2024)。然而,现有预测模型大多将不同年级儿童混合建模,忽略了预测因子重要性的动态变化。分年级建模有助于揭示DD认知机制的发展轨迹,为分阶段筛查提供依据,但这一方向的研究尚属空白。
集成学习(Ensemble Learning,EL)为应对上述数据困境提供了新的技术路径。其能够通过结合多个基模型的预测优势,有效降低模型的过拟合风险,以提高模型的鲁棒性和预测性能(Sagi & Rokach,2018)。其中,Stacking集成策略在处理高维特征、小样本数据等方面展现出独特优势,其层级化学习结构能够更好地适应复杂的数据模式(Lazzarini et al.,2023)。然而,将Stacking专门应用于汉语发展性阅读障碍的小样本认知行为数据,尚属空白。同时,针对数据不均衡问题,过采样技术(Over-sampling)则展现出独特优势。SMOTEENN(Synthetic Minority Over-sampling Technique with Edited Nearest Neighbors)组合过采样技术通过将合成新样本与数据清洗两阶段进行融合,能有效剔除可能产生的噪声点和重叠样本,最终得到一个更纯净、更易于学习的平衡数据集(Husain et al.,2025)。该技术已在部分教育预测场景中得到应用,但在汉语阅读障碍领域尚未见报道。
基于上述分析,本研究尝试融合SMOTEENN过采样与Stacking集成学习策略,构建适用于真实教学场景(小样本、不均衡数据)的高精度、高稳健性DD预测模型,并利用SHAP可解释性技术识别核心认知预测因子。具体而言,试图探讨以下问题:(1)在真实教学场景的小样本、不均衡数据的条件下,能否构建出高精度且高稳健性的汉语DD预测模型?(2)DD的核心认知预测因子有哪些?(3)核心预测因子的重要性是否会随儿童年级发展而变化?
2 方法
2.1 被试
本研究的原始数据来源于新疆乌鲁木齐市某所普通小学1~5年级学生,从每个年级各抽取一个班级,共238名儿童参与本次数据收集。我们对所有参与的儿童均实施了一对一的阅读与认知能力测验。
阅读障碍的纳入标准参考《汉语发展性阅读障碍诊断与干预的专家意见》(王久菊等,2023):字词阅读准确性分数低于同年级平均水平1.5个标准差,或字词阅读准确性低于同年级水平1个标准差,且字词朗读流畅性分数低于同年级平均水平1.5个标准差。此外,认知能力测验中至少有一项的分数低于同年级平均水平1个标准差。同时,依据《联合瑞文测验》测得的非言语智商(IQ)需超过80分。
在剔除无效数据后,得到219份有效数据,并依据纳入标准最终筛查出37名阅读障碍(DD)风险儿童和182名正常(TD)儿童。每位参与者的监护人均书面签署了知情同意书,所有儿童自愿参与本次测试,并在测试结束后均可获得小礼物一份。
2.2 测验项目
本研究所使用的全部测验工具均源自北京师范大学舒华教授团队所研发的标准化阅读障碍筛查测验(Shu et al.,2006;Xue et al.,2013;Su et al.,2015;Liu et al.,2017)。后由王久菊等人(2026)将纸质版测验转化成数字化方式呈现在测评系统中,该系统以两个PAD为媒介展示测验内容及记录信息,分别为被试端和主试端。在被试端,儿童将看到视觉阅读任务的材料。而在主试端,则由主试根据儿童的回答和反应记录相关信息。在使用期间,我们确保了充分的授权和合规性。同时,这些测验工具在以往研究中表现出较高的内部一致性和结构效度,能够有效地区分汉语发展性阅读障碍儿童与正常儿童,为本研究提供了可靠的数据基础。在整个使用过程中符合学术伦理规范,保障了研究的科学性和可重复性。测验具体内容如下。
2.2.1 阅读能力测验
(1)汉字命名
本测验为汉字阅读准确性测验,测验任务由150个汉字组成,共分为10页,每页15个汉字,且难度逐渐增加。任务开始时,要求儿童依次读出PAD屏幕上所呈现的汉字,主试人员在PAD上实时记录被试读对的汉字,每答对一个项目计1分,总分为被试读对汉字的总数。
(2)一分钟读字
本测验用于考察儿童在有限时间内(1分钟)识别单个汉字的流畅性。该测验共分为2个题本,每个题本由100个不同的汉字组成。任务开始时,要求儿童又快又准地依次读出PAD屏幕上呈现的汉字表,主试人员在PAD上实时记录被试读对的汉字,每答对一个项目计1分,PAD自动记录被试读对汉字的总数,总分为2次测验的平均分。
(3)词表朗读
本测验为词语阅读流畅性测验,该测验共分为2个题本,每个题本由90个不同的双字词语组成。任务开始时,要求儿童又快又准地依次读出PAD屏幕上呈现的词语表,主试人员在PAD上实时记录被试读对的词语,每答对一个项目计1分,PAD自动记录被试读对词语的总数,总分为2次测验的平均分。
(4)拼音朗读
本测验为拼音阅读流畅性测验,该测验由120个单字拼音组成。任务开始时,要求儿童又快又准地依次读出PAD屏幕上呈现的拼音表,主试人员在PAD上实时记录被试读对的项目,每答对一个项目计1分,总分为儿童读对的拼音总数。
2.2.2 认知能力测验
(1)音位删除
本测验为语音意识测验,用于测查儿童的语音音位的能力。任务开始时,主试人员在主试端PAD播放指导语和每一条测试题目,并根据实时记录被试的回答。任务要求儿童回答录音中每个音节在删去一部分后,剩下的音读什么。例如“给定音节为‘/mei4/’,不发‘/m/’的音,剩下的音读什么?(/ei4/)”本测验共呈现20个项目,总分为儿童正确完成删音任务的项目总数。
(2)语素产生
本测验为语素意识测验,用于测查儿童对词中单字的意义的辨别和操纵能力。任务开始时,首先给儿童提供一个原始语素(例如“书包的包”),要求儿童根据原始语素自行组一个同义语素词(例如“背包”)和一个不同义语素词(例如“钱包”),并由主试在PAD上实时记录被试的回答。该测验共呈现10个项目,总分为正确组词的总数。
(3)快速命名
本测验为快速命名测验,测查儿童的快速命名能力。任务由5个数字(1,2,3,5,8)以随机顺序呈现,从左至右排列8次,共8行,每行5个数字。任务开始时,要求儿童从左至右逐行快速准确地朗读所有数字,主试负责记录完成的时间。该测验重复2次,并以2次平均反应时作为该测验得分。
(4)字形判断
本测验为正字法意识测验,测查儿童对汉字组合规则的掌握。主试人员将PAD交给儿童,要求儿童又快又准地判断呈现的文字或符号是否符合汉字的正字法规则。材料由45个真字和45个非字(包括15个部件位置错误非字、15个部件错误非字和15个镜像字)组成。被试每答对一个项目计1分,PAD自动记录儿童按键的正确率。
除此上述指标外,我们还要求各班语文老师根据班上每个儿童的成绩及平时表现对其进行等级评定,分为三级:“优秀”“中等”“较差”,形成教师评定语文水平等级表。
2.3 数据编码
在构建预测模型之前,先将原始数据进行预处理,对分类变量进行标准化编码:性别被重新编码为“1=男生”和“0=女生”;年级被重新编码为“1=低年级(1~3年级)”和“2=高年级(4~5年级)”;教师评定语文水平等级被重新编码为“1=较差”“2=中等”“3=优秀”;是否患有阅读障碍被重新编码为“0=否”和“1=是”。其他阅读及认知相关能力测试分数,直接采用原始数据进行处理。
2.4 构建集成预测模型
2.4.1 建立基模型
本研究选取阅读障碍预测领域应用频次最高的8种机器学习算法(卜晓鸥 等,2023),分别为支持向量机(SVM)、逻辑回归(LR)、K近邻(KNN)、随机森林(RF)、朴素贝叶斯(NB)、决策树(DT)、梯度提升(GB)、多层感知机(MLP),基于原始数据集完成各基模型的初始训练。
2.4.2 引入过采样技术
本研究面临的核心挑战之一在于原始数据集中阅读障碍儿童和正常儿童样本量存在严重不均衡(182 TD儿童:37 DD风险儿童)的问题。为充分挖掘有限少数类样本(阅读障碍儿童)中的潜在信息,有效克服机器学习模型在不均衡数据上倾向于预测多数类(正常儿童)的固有偏倚,本研究引入了过采样技术。过采样是解决数据集中类别不均衡的一种直接方法,其核心思想是通过线性插值等方式增加训练集中少数类样本的数量,使其与多数类样本的数量达到平衡(Yang et al.,2017)。其中,SMOTEENN是一种组合过采样策略,分为两个阶段:第一,过采样阶段:首先应用SMOTE 算法通过线性插值自动生成合成样本以平衡类别分布;第二,欠采样阶段:应用ENN法则移除那些与k个最近邻中多数类别标签不一致的样本,达到数据清洗的目的。这种“先过采样,后欠采样(清洗)”的策略能有效剔除SMOTE可能产生的噪声点和重叠样本,最终得到一个更纯净、更易于学习的平衡数据集合(Husain et al.,2025)。因此,本研究选用SMOTEENN组合过采样对原始数据集进行优化,为后续建模提供良好的数据基础。
2.4.3 构建Stacking集成预测模型
为融合多种机器学习算法的优势,并依此构建一个兼具高精度与高稳健性的预测模型,本研究采用Stacking集成学习策略。其核心思想是通过一个元学习器(Meta-Learner)来最优地整合多个基学习器(基模型)地预测结果,以克服单一模型可能存在的偏倚或局限性。本研究的Stacking集成预测模型构建流程如图1所示,具体步骤如下。
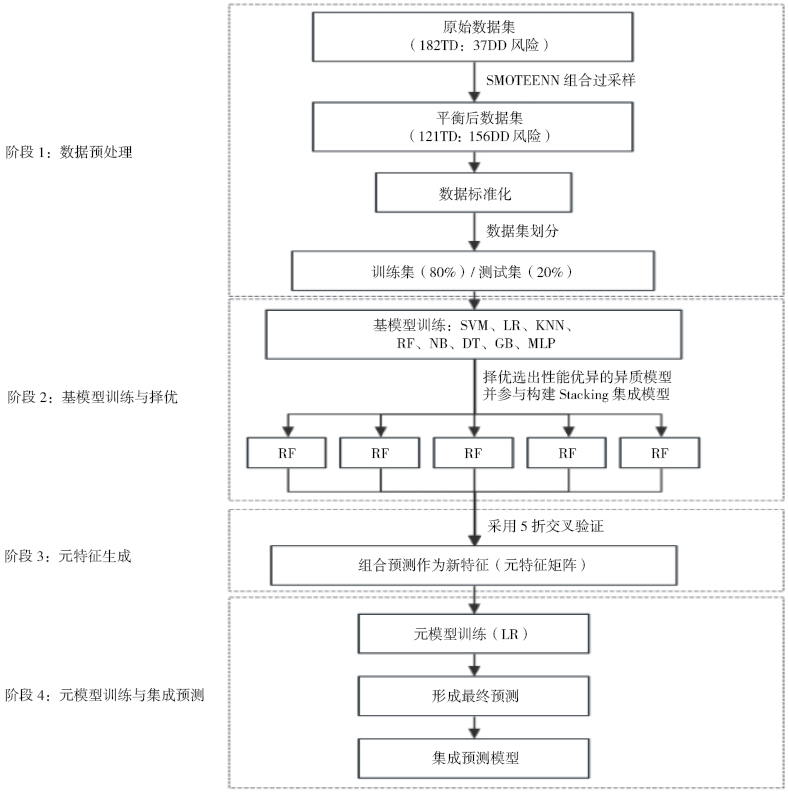
图 1 构建SMOTEENN-Stacking集成预测模型流程图
Figure 1 Flowchart of the SMOTEENN-Stacking ensemble prediction model construction process
(1)数据预处理:采用SMOTEENN组合过采样对原始数据集(182 TD:37 DD风险)进行处理,得到一个平衡后的新数据集(121 TD:156 DD风险)。
(2)基模型优化与择优:使用平衡后的新数据集分别优化8种基模型(SVM、LR、KNN、RF、NB、DT、GB及MLP)。根据各模型在曲线下面积(Area Under the Curve,AUC)、召回率(Recall)、准确率(Accuracy)、精确率(Precision),以及F1分数等关键指标上的表现,从中筛选出5种性能最优异的基模型(RF、GB、LR、SVM、MLP)进入下一阶段的集成学习。
(3)元特征生成:采用5折交叉验证生成用于训练元学习器的元特征(Meta-features)。其将训练集均分为5份,对于每一个基模型,依次使用其中的4份数据训练,并在剩下的1份验证集上进行预测,输出其属于阅读障碍类别的预测概率。在遍历全部5折后,即可得到每个基模型在整个训练集上的一维预测概率向量。随后,将上述5个优化后的基模型所产生的5个预测概率向量横向拼接,形成一个全新的维的特征矩阵(N为训练样本数)。
(4)元模型训练与集成预测:首先,需要选择一个相对简单且稳健的线性模型作为元学习器,以学习如何为各基模型的预测结果分配最优的权重组合,从而做出最终决策。本研究中,采用逻辑回归(LR)作为元学习器,因其能够有效捕捉基模型预测间的线性与非线性交互,输出结果具有概率校准特征并且模型简洁度高,从而可以避免层级过深导致的过拟合风险。最终预测结果由元学习器对基模型输出的加权融合
产生。
2.4.4 运用SHAP可解释性分析技术
在构建集成预测模型的基础上,为了深入探究模型在预测过程中有哪些预测因子起到核心预测作用,本研究采用SHAP(SHapley Additive exPlanations)框架对训练完成的集成模型进行可解释性分析。SHAP是一种基于博弈论的机器学习模型解释方法,通过计算特征对预测结果的边际贡献来量化每个特征的影响。其核心思想是将特征视为合作博弈中的参与者,计算每个特征的Shapley值以评估其对预测结果的贡献,是解决“黑箱模型”可解释性问题的核心技术。其通过计算每个特征SHAP绝对值的均值并进行排序,获得真正反映预测影响力的特征重要性排名(Antonini et al.,2024)。
2.4.5 年级特异性模型的建立
为探究DD预测因子在不同发展阶段的作用,我们分别针对低年级(1~3年级)和高年级(4~5年级)两个子样本集。分别构建了独立的Stacking集成预测模型,通过对比分析阅读能力和核心认知变量在儿童不同发展阶段的重要性排序与预测贡献度的动态变化轨迹。
2.5 模型性能评估指标
为全面、客观地评估预测模型的性能,本研究采用了5个广泛使用的指标对模型性能进行综合评估。具体包括以下指标。
(1)准确率(Accuracy):是指所有预测正确的样本占样本总数的比例。该指标综合反映了预测模型的整体正确分类能力。
(2)精确率(Precision):是指在所有被模型预测为阳性的样本中,真正为阳性的比例。该指标衡量了模型预测阳性结果的可靠性。
(3)召回率(Recall):又称为灵敏度(Sensitivity),
是指在所有真实为阳性的样本中,被模型正确预测出来的比例。在本研究中,高召回率意味着能够找出真实阅读障碍儿童的比例很高,即漏诊率低。该指标是阅读障碍筛查任务中最关键的指标之一。
(4)F1分数(F1-score):它是一个综合指标,是精确率和召回率的调和平均数,用于平衡精确率与召回率。当二者冲突时,F1分数比单一的准确率能更好地评估模型的性能。
(5)受试者工作特征曲线下面积(Area Under the Curve):AUC被定义为ROC曲线下的面积,该指标衡量的是模型的排序能力(将正样本排在负样本之前的概率)。其数值越接近1,说明模型的分类性能越好,是评价模型综合性能的重要指标。
本研究将AUC作为核心参考指标,主要基于以下考量:第一,AUC同时兼顾模型对正负样本的区分能力,避免单一指标(如准确率)在不均衡数据中的误导性;第二,AUC评估模型在所有分类阈值下的整体表现,消除人为设定阈值的主观影响;第三,在临床筛查场景中,AUC直接反映模型对高风险个体的优先识别能力;第四,在阅读障碍预测领域,AUC已被广泛接受为模型性能的黄金标准(Wang & Bi,2022;Han & Joe,2024)。因此,本研究采用AUC作为模型优化的首要目标与性能排序的核心标准,同时辅以召回率、准确率、精确率等指标进行多维度验证,确保模型在真实筛查场景中的实用性与可靠性。
3 结果
3.1 SMOTEENN对不均衡数据问题的改善及模型性能提升
为应对原始数据集中TD儿童与DD风险儿童类别严重不均衡(182:37)问题,本研究选取了SMOTEENN组合过采样技术对训练集进行平衡处理。该技术融合了过采样(SMOTE)与欠采样(ENN)策略,能够在合成少数类新样本的同时,清理边界噪声,理论上可生成质量更高、分布更合理的平衡数据集。
表1对比了各基模型在原始不均衡数据集与经SMOTEENN技术处理后的平衡数据集上的关键性能指标。结果表明,经SMOTEENN处理后,所有基模型的性能均得到全方位、大幅度的提升。尤为关键的是,召回率(Recall)从基于原始数据集的最优模型的57.14%全面提升最高至100%。这意味着“漏诊”的概率大幅降低,即模型大幅增强对少数类(阅读障碍儿童)样本的识别能力,有力地证明了过采样技术对于处理小样本不均衡数据的有效性,为后续构建高精度、高泛化性的集成预测模型奠定了可靠的数据基础。
表 1 使用原始数据集和SMOTEENN过采样处理后的数据集构建的各基模型的性能指标
Table 1 Performance metrics of each base model built using the original dataset and the dataset oversampled with SMOTEENN
| 过采样技术 | 样本分布(TD:DD风险) | 模型名称 | 性能参数 | ||||
| AUC | Recall | Accuarcy | Precison | F1-score | |||
| 原始数据集 | 182:37 | MLP* | 0.9305 | 0.5714 | 0.8864 | 0.6667 | 0.6154 |
| LR | 0.8533 | 0.4286 | 0.8864 | 0.7500 | 0.5455 | ||
| RF | 0.8263 | 0.4286 | 0.8864 | 0.7500 | 0.5455 | ||
| NB | 0.8185 | 0.4286 | 0.7727 | 0.3333 | 0.3750 | ||
| GB | 0.8069 | 0.5714 | 0.9091 | 0.8000 | 0.6667 | ||
| SVM | 0.7992 | 0.4286 | 0.8864 | 0.7500 | 0.5455 | ||
| KNN | 0.7876 | 0.4286 | 0.8864 | 0.7500 | 0.5455 | ||
| DT | 0.6911 | 0.5714 | 0.7727 | 0.3636 | 0.4444 | ||
| SMOTEENN | 121:156 | MLP* | 0.9987 | 1.0000 | 0.9621 | 0.9518 | 0.9753 |
| RF | 0.9974 | 1.0000 | 0.9464 | 0.9118 | 0.9538 | ||
| LR | 0.9948 | 0.9677 | 0.9643 | 0.9677 | 0.9677 | ||
| SVM | 0.9948 | 0.9677 | 0.9464 | 0.9375 | 0.9524 | ||
| GB | 0.9935 | 0.9677 | 0.9643 | 0.9677 | 0.9677 | ||
| KNN | 0.9929 | 0.9677 | 0.9107 | 0.8824 | 0.9231 | ||
| NB | 0.9781 | 0.9355 | 0.9286 | 0.9355 | 0.9355 | ||
| DT | 0.8839 | 0.9677 | 0.8929 | 0.8571 | 0.9091 | ||
注:*表示每种策略下性能最优的基模型。
3.2 Stacking集成预测模型的性能
基于各基模型在优化数据集上的综合表现,本研究筛选MLP、RF、LR、SVM和GB五种异质且性能优异的模型参与Stacking集成学习阶段。本研究中,我们将逻辑回归(LR)作为Stacking集成策略中的元学习器,旨在融合各基模型的优势,构建一个高精度且高稳健性的集成预测模型。如表2所示,通过对比Stacking集成模型与单一最优模型MLP的性能指标,并从多维度考察模型的综合性能。
表 2 Stacking集成模型与最优单一模型(MLP)详细性能指标对比
Table 2 Detailed performance comparison between the stacking ensemble model and the optimal single model (MLP)
| 模型名称 | AUC | Recall | Accuracy | Precision | F1-score | CV-AUC | CV-STD |
| Stacking集成模型 | 0.9961 | 0.9677 | 0.9643 | 0.9677 | 0.9677 | 0.9968 | 0.0036 |
| MLP | 0.9987 | 1.0000 | 0.9621 | 0.9518 | 0.9753 | 0.9902 | 0.0085 |
表2的数据表明,单一最优模型MLP在测试集上表现出色,尤其在召回率(Recall)方面达到了1.0000,这意味着它成功识别了所有阅读障碍儿童,避免了“漏诊”的风险。然而,MLP的精确率(Precision)相对较低,暗示可能存在一定的“误诊”风险。相比之下,Stacking集成模型在各项指标上取得了更佳的平衡,其召回率(Recall)、准确率(Accuracy)、精确率(Precision)与F1-score均稳定在0.9677左右。这种均衡性显著降低了误诊与漏诊的双重风险,更符合临床筛查对模型稳定性的严苛要求。
为深入评估模型稳健性与泛化能力,进一步引入了交叉验证曲线下面积(CV-AUC)和交叉验证标准差(CV-STD)两项指标。其中,CV-AUC是通过5折交叉验证计算的平均AUC值,反映模型在多个数据子集上的平均泛化能力,避免了单次数据划分的偶然性;而CV-STD为5折交叉验证AUC值的标准差,来衡量模型性能的波动性,即数值越低,表明模型在不同数据子集上表现越稳定,过拟合风险越低。通过数据对比发现,Stacking集成模型的CV-AUC值达0.9968,不仅高于其测试AUC值,也明显优于MLP的CV-AUC值,表明其在不同数据子集上具有更优且稳定的平均泛化性能。同时,Stacking集成模型的CV-STD极低,仅为MLP的42.4%,说明其性能波动性小,体现出更稳健的性能。
图2的预测误差箱线图直观印证了上述结果。Stacking集成模型的箱线图显示其预测误差分布紧凑,箱体较短、四分位距较小,且无明显异常值,反映了其高度稳健的性能。而MLP模型,其误差分布相对分散,预示着在不同数据集上可能存在较大的性能波动,泛化能力相对较弱。此外,图中其他单一模型(例如GB、DT)呈现更为分散的误差分布(箱体较长且存在异常值),从侧面更加凸显了Stacking集成策略通过异质模型融合,在提升模型稳健性方面的显著优势。
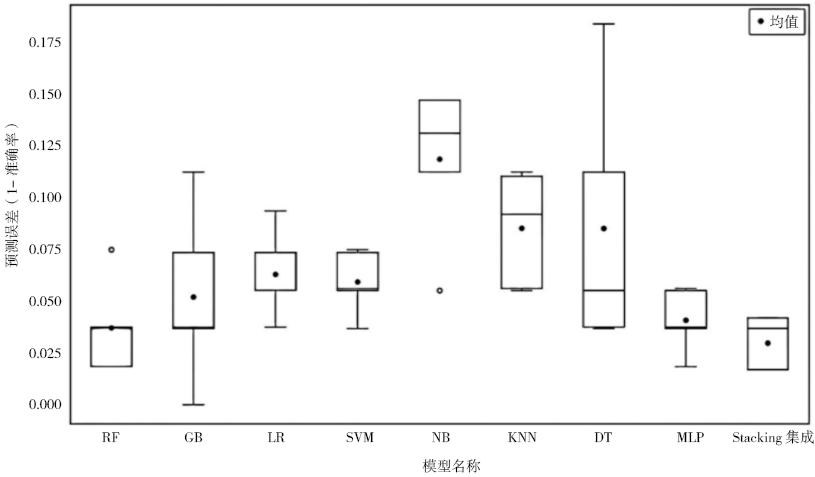
图 2 各模型预测误差对比箱线图
Figure 2 Box plot comparing the prediction errors of each model
3.3 基于SHAP值的核心预测因子分析
为深入探究阅读和认知能力的各项预测因子在预测汉语发展性阅读障碍中的相对重要性,采用SHAP框架对训练完成的Stacking集成模型进行可解释性分析。SHAP作为一种基于博弈论的解释方法,通过计算每个特征对预测结果的边际贡献(Shapley值),量化各预测因子的重要性及其影响方向,以有效地解决“黑箱模型”的可解释性问题。
在本研究中,针对集成模型的特点,采用适用于异质模型组合的kernelSHAP解释器计算测试集样本的SHAP值,通过计算每个预测因子SHAP绝对值的均值(mean(|SHAP|)),获得全局预测因子重要性排名。该指标能真实反映各预测因子对模型输出的平均影响幅度。基于SHAP分析结果,各预测因子对阅读障碍预测的全局重要性排名如图3所示(按(mean(|SHAP|))降序排列)。
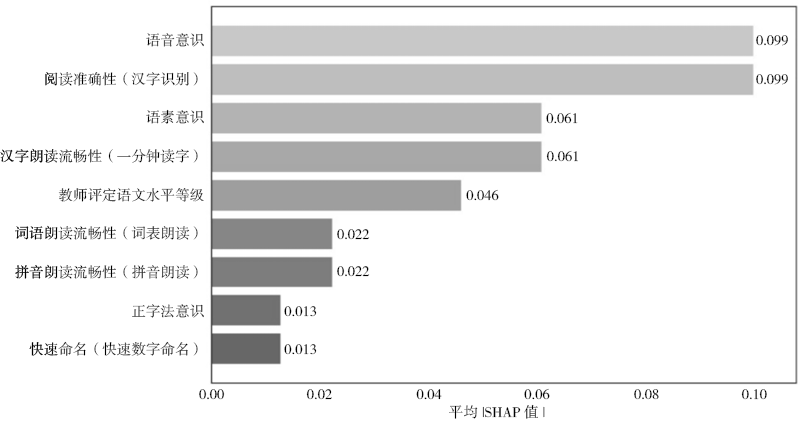
图 3 全局预测因子重要性排名
Figure 3 Ranking of the importance of global predictive factors
由图3可以看出,语音意识和阅读准确性二者的SHAP重要性得分最高,表明语音意识和阅读准确性是区分汉语发展性阅读障碍的最强预测因子。除此之外,语素意识、字词朗读流畅性、教师评定语文水平等级、正字法意识、快速命名等预测因子也对预测起到了重要作用。
3.4 预测因子的发展轨迹:分年级建模对比
为探究各预测因子在发展性阅读障碍识别中的特异性作用以及随年级发展的动态发展轨迹,本研究分别构建了低年级(1~3年级)和高年级(4~5年级)的特异性Stacking模型,并比较其SHAP特征重要性排名,结果如表3所示。
由表3的对比结果表明,从低年级到高年级,预测因子的重要性发生了显著的结构性变化。具体而言,阅读准确性、字词朗读流畅性(汉字朗读流畅性和词语朗读流畅性)、语音意识、正字法意识和语素意识等直接反映阅读效率与自动化程度的因子,其重要性随年级升高而显著增长;而教师评定语文水平等级、快速命名和拼音朗读流畅性等因子的重要性则随年级升高而降低。其中,“教师评定语文水平等级”从低年级的第1位降至高年级的第9位,发生了断崖式下降。
表 3 核心预测因子重要性对比:低年级vs高年级
Table 3 Comparison of the importance of core predictive factors: Lower grades vs. Higher grades
| 低年级(1-3年级) | 高年级(4-5年级) | 变化趋势 | ||
| 重要性排名 | 预测因子 | 预测因子 | 重要性排名 | |
| 1 | 教师评定语文水平等级 | 阅读准确性 | 1 | ↑2 |
| 2 | 拼音朗读流畅性 | 汉字朗读流畅性 | 2 | ↑6 |
| 3 | 阅读准确性 | 词语朗读流畅性 | 3 | ↑3 |
| 4 | 快速命名 | 语音意识 | 4 | ↑1 |
| 5 | 语音意识 | 快速命名 | 5 | ↓1 |
| 6 | 词语朗读流畅性 | 正字法意识 | 6 | ↑1 |
| 7 | 正字法意识 | 拼音朗读流畅性 | 7 | ↓5 |
| 8 | 汉字朗读流畅性 | 语素意识 | 8 | ↑1 |
| 9 | 语素意识 | 教师评定语文水平等级 | 9 | ↓8 |
注:“↑”表示低年级到高年级重要性上升;“↓”表示低年级到高年级重要性下降。
4 讨论
4.1 SMOTEENN-Stacking集成框架的方法学突破
本研究首先探讨了在小样本、不均衡数据条件下构建高精度、高稳健性DD预测模型的可行性。结果表明,所构建的SMOTEENN-Stacking集成框架在方法学上实现了一定的突破。
在数据处理层面,SMOTEENN过采样有效缓解了数据集类别不均衡(TD儿童:DD风险儿童≈5:1)对模型训练的负面影响。如表1所示,经过SMOTEENN处理后,所有基模型的各项性能指标均得到提升。尤为关键的是,召回率从基于原始数据集最高的57.14%提升至最高100%,极大降低了“漏诊”风险。这验证了混合过采用技术在提升认知行为数据质量、克服模型固有偏倚方面的有效性(Han & Joe,2024)。
在模型集成层面,Stacking集成策略将LR作为元学习器以更好地融合RF、GB、LR、SVM、MLP五种异质且性能优异的基模型的优势,在各项性能指标上取得了更佳的平衡(AUC=0.9961、Recall=0.9677、Accuracy=0.9643、Precision=0.9677、F1-score=0.9677)。相较于单一最优模型MLP(Recall=1.0000、Precision=0.9518),Stacking模型在保持高召回率的同时,表现出更高的精确率,进一步降低了“误诊”风险。此外,其交叉验证标准差(CV-STD=0.0036)低于MLP(CV-STD=0.0085),且预测误差分布更为紧凑,如图2所示,证明该方法通过模型融合有效提升了泛化能力与稳健性,进一步降低了过拟合风险。这与集成学习提升模型鲁棒性的理论预期一致(Sagi & Rokach,2018),并为应对教育领域常见的小样本、不均衡数据问题提供了可复用的高效建模方案。
4.2 汉语发展性阅读障碍核心预测因子分析
本研究通过SHAP分析发现,语音意识与阅读准确性是预测汉语发展性阅读障碍的两个最核心的预测因子(SHAP重要性排名并列第一)。这一结果与Wang和Bi(2022)基于GA-BPNN模型的研究高度一致。尽管汉字作为表意文字,但语音意识的重要性仍不容忽视,其原因可能是语音解码是阅读习得初期的基础通路,语音意识缺陷会阻碍字形与语音、语义的快速、自动化联结,从而影响阅读流畅性与理解深度。本研究采用的集成学习模型能够更稳健地捕捉变量间的复杂非线性关系,这可能有助于揭示出在传统线性分析中易被掩盖的语音通路的基础作用。
与此同时,阅读准确性也是核心预测因子之一,凸显了其在汉语DD筛查中的重要价值。阅读准确性直接反映了儿童对汉字形—音—义联结的掌握程度以及词汇识别的自动化水平。在汉字系统下,庞大的字集和复杂的字形使得准确、快速的单字识别成为阅读能力发展的基石。本研究发现,这一结果性指标本身就是一个极其敏感的区分指标,表明在行为筛查中,对字词识别准确性的直接测量至关重要。这一结果也表明,在数据驱动的视角下,语音通路和字词解码的自动化能力可能提供了更稳定、更具鉴别力的预测信号。
4.3 预测因子随年级动态变化的探讨
为探究预测因子的发展轨迹,本研究分别构建了低(1~3年级)、高(4~5年级)年级特异性模型。结果显示,汉语发展性阅读障碍的核心预测因子随年级升高发生系统性演变:低年级模型更多依赖综合性学业评价(如教师评定语文等级水平)和基础认知技能(如拼音朗读流畅性);而高年级模型则转向以阅读准确性、字词朗读流畅性等直接反映阅读效率的指标为主。这一发现不仅具有实践指导价值,也为阅读发展的认知理论提供了来自预测模型的实证证据。
首先,这一转变模式与阅读能力发展的阶段性理论相符(Goswami,2015)。在低年级“学习阅读”的初期,儿童的阅读表现与基础认知技能(如语音加工、拼音解码)的熟练度紧密相关。拼音朗读流畅性作为语音意识与字形-音位规则应用的体现,其重要性与此阶段的教学重点一致。同时,教师评定作为一个整合了儿童课堂行为、作业表现和初步阅读能力的综合性外部效标,在认知缺陷尚未完全外显为严重阅读困难时,能够提供有效的补充预测信息。
随着年级升高,阅读任务的核心从“解码”转向“通过阅读来学习”,对阅读的自动化与效率提出了更高要求(Goswami,2015)。此时,任何潜在的加工缺陷都会更直接、更严重地表现为阅读准确性和流畅性的落后。本研究的结果表明,到高年级,这些直接的“阅读效率指标”成为区分DD儿童最敏感的指标。这一发现与纵向研究揭示的认知技能预测力随年级动态变化的规律相契合(Blockmans et al.,2024)。
此外,教师评定的重要性在4~5年级急剧下降。可能的原因是,随着学业复杂化,影响学业表现的因素增多(如学习策略、动机),阅读困难可能被部分补偿策略掩盖,使得教师的直观评价效力降低。拼音朗读流畅性重要性的下降,则可能反映了基础解码技能在低年级后出现的“天花板效应”,而更高层级的阅读整合与自动化能力成为制约进一步发展的关键瓶颈。这一“从基础技能到阅读自动化”的预测因子演变轨迹,提示对DD的筛查与评估必须具备发展性视角。低年级筛查应重视基础语音技能和教师的观察,而高年级筛查则应聚焦于阅读准确性和流畅性等效率指标,从而为实现分年级的精准识别与干预提供了明确的靶点。
5 局限与未来展望
本研究仍存在一定的局限性,主要包括以下方面。
首先,本研究的样本规模有限(N=219)且来源单一(来自乌鲁木齐市某小学),可能会限制模型的泛化能力;同时缺乏纵向追踪数据,难以验证预测因子的长期稳定性。未来考虑扩大取样范围,建立地区常模,并开展追踪研究以增强模型生态效度。
其次,本研究仅采用认知行为数据进行建模,未纳入眼动、脑电等神经生理指标,限制了对障碍成因的深层解释。后续可引入多模态数据融合技术,结合行为与眼动等神经生理指标,构建更全面、更具解释力的预测模型。
最后,SMOTEENN过采样技术虽缓解了数据不均衡问题,但合成样本可能偏离真实分布,存在边界噪声与偏差放大的风险。未来可探索生成式对抗网络(GAN)等更先进的样本生成技术,或通过扩大实际筛查规模直接获取足量平衡数据,以提升模型的稳健性与生态效度。
6 结论
本研究首次将“SMOTEENN-Stacking”集成学习框架应用于汉语发展性阅读障碍预测领域,在提升模型预测效能的同时有效弥补了现有研究忽略年级动态变化的不足。该模型表现出优异的预测性能与较高的稳健性,各项性能指标优异(AUC=0.9961、Recall=0.9677、Accuracy=0.9643、Precision=0.9677、F1-score=0.9677)。
本研究在理论层面,证实了语音意识与阅读准确性的核心预测地位,并初步揭示了预测因子从“基础认知主导(低年级)”到“阅读效率主导(高年级)”的年级动态转变;在技术层面,提供了一个适配真实教育场景的低成本高精度的建模方案;在实践层面,为大规模基层筛查与分阶段干预提供了精准靶点。尽管本研究存在样本与方法学局限,但为汉语发展性阅读障碍的早期识别与机制研究提供了重要的理论与技术支撑,也为同类小样本不均衡数据的研究开辟了新路径。
参考文献
[1] 卜晓鸥, 王耀, 杜亚雯, 王沛. (2023). 机器学习在发展性阅读障碍儿童早期筛查中的应用. 心理科学进展, 31(11), 2092-2105.
[2] 陈建军, 刘佩瑶, 刘佃振, 乔福强, 梁永胜. (2025). 汉语发展性阅读障碍儿童语音加工缺陷的发生机制及干预的研究现状与展望. 现代特殊教育, (8), 18-26.
[3] 董琼, 李虹, 伍新春, 潘敬儿, 张玉平, 阮氏芳. (2012). 汉语发展性阅读障碍儿童的阅读相关认知技能缺陷. 中国临床心理学杂志, 20(6), 798-801, 764.
[4] 孟祥芝, 沙淑颖, 周晓林. (2004). 语音意识、快速命名与中文阅读. 心理科学, (6), 1326-1329.
[5] 任梦洁, 申仁洪. (2024). 汉语发展性阅读障碍语音意识缺陷的基本特征、发生机制和干预模式. 现代特殊教育,(18),65-73.
[6] 王久菊, 孟祥芝, 李虹, 崔新, 洪恬, 杨斌让, ... 王玉凤. (2023). 汉语发展性阅读障碍诊断与干预的专家意见. 中国心理卫生杂志, 37(3), 185-191.
[7] 王久菊, 李虹, 张玉平, 张亚静, 王穗苹, 赵晶晶, ... 舒华. (2026). 汉语发展性阅读障碍数字化诊断测验的研发与应用. 中国心理卫生杂志, 40(2), 93-99.
[8] 王懋云, 郭广行, 陈思, 张曼洁, 董源. (2025). 基于图卷积神经网络的儿童阅读障碍分类识别研究. 太原师范学院学报(自然科学版), 24(2), 24-28.
[9] 徐世勇, 彭聃龄, 薛贵, 谭力海. (2001). 汉语发展性阅读障碍儿童心理机制的初步研究. 心理发展与教育, (4), 12-16, 22.
[10] Antonini A S, Tanzola J, Asiain L, Ferracutti G R, Castro S M, Bjerg E A.& Ganuza M L. (2024). Machine Learning model interpretability using SHAP values: Application to Igneous Rock Classification task. Applied Computing and Geosciences, 23, 100178.
[11] Blockmans L, Kievit R, Wouters J, Ghesquière P & Vandermosten M. (2024). Dynamics of cognitive predictors during reading acquisition in a sample of children overrepresented for dyslexia risk. Developmental Science, 27(1), e13412.
[12] Chen X, Hao M, Geva E, Zhu J & Shu H. (2009). The role of compound awareness in Chinese children’s vocabulary acquisition and character reading. Reading and Writing, 22(5), 615-631.
[13] Gabrieli J D. (2009). Dyslexia: a new synergy between education and cognitive neuroscience. Science, 325(5938), 280-283.
[14] Goswami U. (2015). Sensory theories of developmental dyslexia: three challenges for research. Nature Reviews Neuroscience, 16(1), 43-54.
[15] Han Y & Joe I. (2024). Enhancing machine learning models through PCA, SMOTE-ENN, and stochastic weighted averaging. Applied Sciences, 14(21), 9772.
[16] Ho C S H, Chan D W O, Tsang S M & Lee S H. (2002). The cognitive profile and multiple-deficit hypothesis in Chinese developmental dyslexia. Developmental psychology, 38(4), 543.
[17] Husain G, Nasef D, Jose R, Mayer J, Bekbolatova M, Devine T & Toma M. (2025). SMOTE vs. SMOTEENN: A study on the performance of resampling algorithms for addressing class imbalance in regression models. Algorithms, 18(1), 37.
[18] Kaisar S. (2020). Developmental dyslexia detection using machine learning techniques: A survey. ICT Express, 6(3), 181-184.
[19] Lazzarini R, Tianfield H & Charissis V. (2023). A stacking ensemble of deep learning models for IoT intrusion detection. Knowledge-Based Systems, 279, 110941.
[20] Liu P D & McBride-Chang C. (2010). What is morphological awareness? Tapping lexical compounding awareness in Chinese third graders. Journal of educational psychology, 102(1), 62.
[21] Liu Y, Georgiou G K, Zhang Y, Li H, Liu H, Song S ... & Shu H. (2017). Contribution of cognitive and linguistic skills to word-reading accuracy and fluency in Chinese. International Journal of Educational Research, 82, 75-90.
[22] Lyon G R, Shaywitz S E & Shaywitz B A. (2003). A definition of dyslexia. Annals of dyslexia, 53(1), 1-14.
[23] Man Kit Lee S, Liu H W & Tong S X. (2023). Identifying Chinese children with dyslexia using machine learning with character dictation. Scientific Studies of Reading, 27(1), 82-100.
[24] McBride-Chang C, Cheung H, Chow B Y, Chow C L & Choi L. (2006). Metalinguistic skills and vocabulary knowledge in Chinese (L1) and English (L2). Reading and Writing, 19(7), 695-716.
[25] Perfetti C A, Tan L H & Siok W T. (2006). Brain-behavior relations in reading and dyslexia: Implications of Chinese results. Brain and Language, 98(3), 344-346.
[26] Płoński P, Gradkowski W, Altarelli I, Monzalvo K, van Ermingen-Marbach M, Grande M, ... & Jednoróg K. (2017). Multi-parameter machine learning approach to the neuroanatomical basis of developmental dyslexia. Human Brain Mapping, 38(2), 900-908.
[27] Sagi O & Rokach L. (2018). Ensemble learning: A survey. Wiley interdisciplinary reviews: data mining and knowledge discovery, 8(4), e1249.
[28] Shamir N, Zivan M & Horowitz-Kraus T. (2019). Six-minute screening test can provide valid information about the skills that underlie childhood reading and cognitive abilities. Acta Paediatrica, 108(7), 1278-1284.
[29] Shu H, McBride-Chang C, Wu S & Liu H. (2006). Understanding Chinese developmental dyslexia: morphological awareness as a core cognitive construct. Journal of educational psychology, 98(1), 122.
[30] Su M, Wang J, Maurer U, Zhang Y, Li J, McBride C., ... & Shu H. (2015). Gene–environment interaction on neural mechanisms of orthographic processing in Chinese children. Journal of neurolinguistics, 33, 172-186.
[31] Tong X, McBride C, Lo J C M & Shu H. (2017). A three-year longitudinal study of reading and spelling difficulty in Chinese developmental dyslexia: The matter of morphological awareness. Dyslexia, 23(4), 372-386.
[32] Usman O L & Muniyandi R C. (2020). CryptoDL: Predicting dyslexia biomarkers from encrypted neuroimaging dataset using energy-efficient residue number system and deep convolutional neural network. Symmetry, 12(5), 836.
[33] Vajs I, Ković V, Papić T, Savić A M & Janković M M. (2022). Spatiotemporal eye-tracking feature set for improved recognition of dyslexic reading patterns in children. Sensors, 22(13), 4900.
[34] Wang R & Bi H Y. (2022). A predictive model for chinese children with developmental dyslexia—Based on a genetic algorithm optimized back-propagation neural network. Expert Systems with Applications, 187, 115949.
[35] Xue J, Shu H, Li H, Li W & Tian X. (2013). The stability of literacy-related cognitive contributions to Chinese character naming and reading fluency. Journal of psycholinguistic research, 42(5), 433-450.
[36] Yang L, Li C, Li X, Zhai M, An Q, Zhang Y, ... & Weng X. (2022). Prevalence of developmental dyslexia in primary school children: A systematic review and meta-analysis. Brain sciences, 12(2), 240.
[37] Yang X, Kuang Q, Zhang W & Zhang G. (2017). AMDO: An over-sampling technique for multi-class imbalanced problems. IEEE Transactions on Knowledge and Data Engineering, 30(9), 1672-1685.
[38] Yeung P S, Ho C S H, Chan D W O & Chung K K H. (2016). Orthographic skills important to Chinese literacy development: The role of radical representation and orthographic memory of radicals. Reading and Writing, 29(9), 1935-1958.



